How Do Web Crawlers Work and Influence SEO?
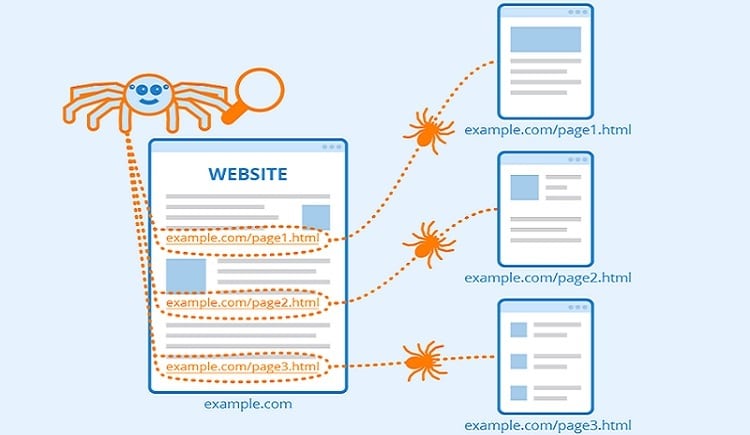
Image Credits: seobility.net
TechsPlace | Have you ever heard the term “web crawler” or “search engine bot”? The thing is that there are lots of search engines out there, and if you wish to run your business online and want to promote your website, you need to know how search engines work. In this post, we’ll analyze the term “web crawler” and try to understand how they work. So get comfortable and have a look!
What’s The Main Goal of a Web Crawler?
It’s a search engine bot that indexes content across the internet. Its key mission is to find out what the webpage is about to retrieve this information later (when needed). The name “web crawlers” is given to them because they access a website automatically and gather data via a special software program. Such bots are usually controlled by search engines. Thanks to them, search engines can provide its users with relevant links in response to their queries. As a result, they can easily generate the list of web pages that users see after they type what they want to find on Google, Bing, etc.
How Do They Work?
Changes are all about us. Technology is constantly evolving, and new things appear on an ongoing basis. The internet is overloaded with a variety of links, and it is impossible to check how many web pages there are on the web. Therefore, a web crawler begins with a seed (it is a list of well-known URLs). First, web crawler bots crawl the pages at those URLs. While they do this, they find hyperlinks to other URLs and so on.
Considering the fact that the internet is overloaded with web pages that could be indexed, this process is endless. Here’s how everything goes on:
- Web crawlers check the importance of each page. Remember that such tools aren’t meant for crawling all available web pages. Their goal is to decide what particular pages they should crawl first (depending on the number of other web pages that are linked to it, the average number of visitors, and lots of other aspects that signify its likelihood). If a webpage has a number of visitors and contains interesting and engaging content, it will be indexed by the search engine first.
- Visiting web pages again. You know that the content of websites is constantly updated. Some posts are removed, whereas others are added. So a web crawler should revisit this website again from time to time to index its latest version.
- Web crawlers choose what page to crawl on the basis of the robots.txt protocol. First, they need to check the robot.txt file that is owned by the webserver of a page. The primary goal of this file is to determine the rules for bots that try to access the hosted website. Such rules define what particular web pages bots can access and what particular links they should follow.
However, there’s only one thing you need to be aware of – every search engine has its own crawlers, and they behave differently. But their main objective is the same – they index websites!
How Web Crawlers Influence SEO?
The overriding purpose of search engine optimization is to improve the website’s usability so that the right people could visit this website from the search engine. Due to SEO tools, websites will be shown up higher in search results.
The algorithm is very simple – if a spider bot doesn’t or can’t crawl your website, it won’t be indexed. Therefore, it won’t appear in search results. So you see that everything is interdependent. If you own a website and wish to get some organic traffic, it is of prime importance for you to double-check if crawler bots aren’t blocked.
What Can Influence Crawlability?
Here are a few things that have a strong impact on crawlability:
- Website Structure. If it is weak, this may cause some crawlability issues. For instance, your website may include webpages that web crawlers can’t access.
- Internal Link Structure. A powerful internal link structure enables a crawler to reach all the web pages in your site structure.
- Server Errors. If you face some server-related issues, this may prevent search bots from accessing your website.
- Broken page redirects also influence crawling.
- Unsupported scripts. Unfortunately, a lot depends on the technology that you use on your website. For example, such scripts as Ajax or Javascript may easily block content from search bots.
- You don’t update your website regularly. It goes without saying that the content that is published on your website is the most crucially important part. Its key objective is to attract visitors and convert them into clients who will soon buy this or that product or service from your website. Your content can also enhance the crawlability of your website. When you update content on a regular basis, search bots will index your website quicker.
As a conclusion, we should add that to rank a website successfully, webmasters should constantly update their website and publish strong and engaging content there. All these tips improve the website’s authority. But you should also constantly monitor if search bots can access your website. Otherwise, the targeted audience won’t see it in search results.

This article is contributed by guest author on techsplace.com.




